追加コスト0円で耐障害化:OCIのNetwork Load Balancer(NLB)で自宅サーバ公開の入口を二重化
自宅サーバを外部公開する“入口”として、OCI(Oracle Cloud Infrastructure)の無料枠を前提にインスタンス(OCI1)を立て、パブリックIP経由で自宅へ転送する構成で運用していました。
ところが、OCI1が起動しているにも関わらずネットワーク通信だけができない現象が発生。コンソール接続して確認するとOS自体は応答していて、ソフトウェア的な破綻(設定ファイルの致命的なミス、サービス停止など)は見つけられませんでした。OCI側の障害情報も特に無し。
さらに厄介だったのは、テスト用途で用意していたもう1台(OCI2)は通常運転だったことです。障害は1台に偏っていて、しかも1日数時間の無通信状態が数回起きています。観測上、障害が起きた時間帯はOCI1だけモニタリングのメトリクスが取れていない状態にもなっていました。
原因調査は続けるとしても、入口が止まるのは困るので「構成で耐える」方向に切り替えました。
今回のゴール:無料のまま入口を止めない
目標はシンプルです。
- 追加コスト0円(無料枠の範囲で完結)
- OCI1が不通でも、自動的にOCI2へ切り替わって通信継続
- 手動でIP付け替えやDNS切替をしない
“原因不明の不通”は再発する前提で、まず単一障害点を潰します。
何が厄介だったか:OCI1だけ外に通信できない
今まで運用していたOCI1は、インスタンス管理画面のOS管理タブにあるCloud Shell接続を用いてコンソール接続できる=OSは生きている状態でした。一方で、メトリクスは取得できておらず、外部からの通信および外部への通信ができない=入口としては死んでいる。しかも、OCI2は正常。
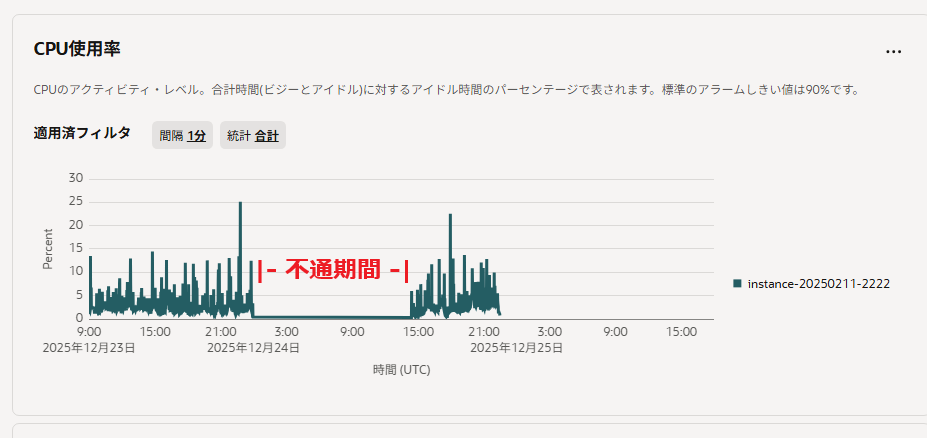
「再起動すれば直るかも」と繰り返しましたが、何も解決しなかったので、原因究明より先に“止めない仕組み”を作ることにしました。
0円で二重化する:Network Load Balancer(NLB)を入口にする
ここで導入したのが Network Load Balancer。略して NLB(Network Load Balancer)です。HTTPのHost名で振り分けるL7ではなく、主にTCP/UDPなどを扱う“入口”として使うイメージです。
大事な点は「無料縛り」との相性で、OCIのドキュメント上 Network Load BalancerはAlways Free 層と明記されています(執筆時点)。
また、ネットワーク料金として インバウンド無料、アウトバウンドも「最初の10TBが無料」という説明が公式の料金ページにあります(ただし上限超過や条件には注意)。
やったことは次のとおり。
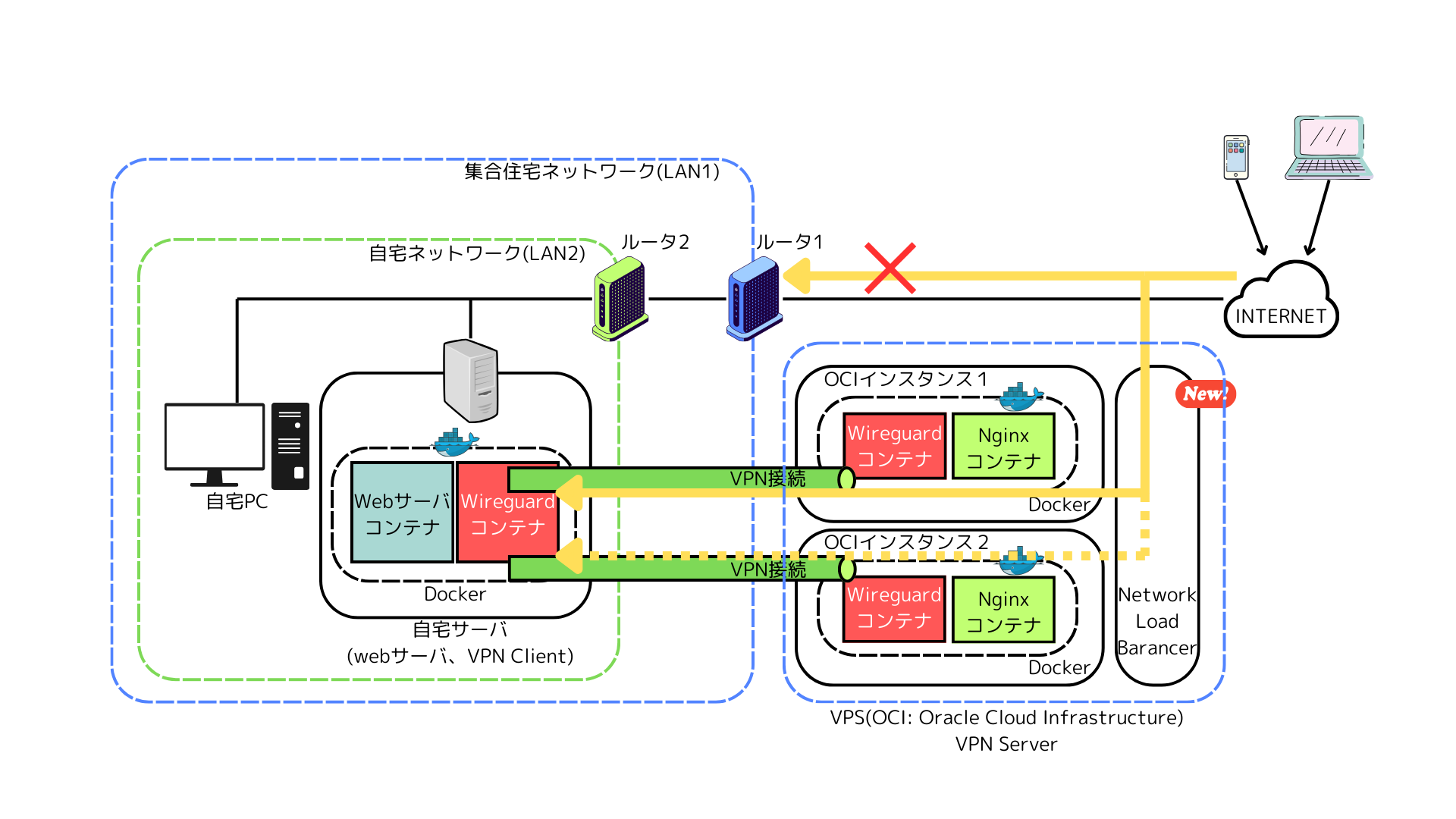
- OCI2にもWireGuardとnginxを導入して、OCI1と同等の入口にする
- NLBを作成し、バックエンドにOCI1/OCI2を登録
- 外部からの入口を「NLB →(OCI1またはOCI2)→ 自宅サーバ」に統一
これでOCI1が不通になれば、バックエンドのヘルスが落ちてローテーションから外れ、OCI2側に寄せる設計になります。
設定手順:NLBの作成(コンソール)
メニューの位置は以下です。
ネットワーキング > ネットワーク・ロード・バランサ > ネットワーク・ロード・バランサの作成
以降、固有名は分からないように、記事用に置き換えています(例:vcn-main、subnet-nlb、instance-a など)。実際はあなたの環境名に読み替えてください。
詳細の追加
- ネットワーク・ロード・バランサ名:nlb-home-entry
- コンパートメント:my-compartment
- 可視性タイプ:パブリック(インターネットから受けたい場合)
- パブリックIPアドレスの割当て:エフェメラルIPv4
(固定化したい場合は予約済IPv4でもOK) - VCN:vcn-main
- サブネット:subnet-nlb
- NSG:今回は未指定(後から付けてもよい)
「無料縛りでまず動かす」が目的なら、ここはシンプルで十分です。
リスナーの構成
今回の用途は「WireGuardや転送など、複数ポート/複数プロトコルをまとめて入口にしたい」だったので、UDP/TCPをまとめて、しかも“任意のポート”で受ける設定にしました。
- リスナー名:listener-any
- トラフィック・タイプ:UDP/TCP
- イングレス・トラフィック・ポート:任意のポートを使用
任意のポートは(ポート0/ワイルドカード)という扱いのようです。
- タイムアウトは、画面の制約に合わせて(例:120秒など)でいったんOK。まずは動かしてから詰めます。
バックエンドの選択(バックエンド・セット)
- バックエンド・セット名:backendset-home
- バックエンドの追加:コンピュート・インスタンスを2台追加
- instance-a(例:10.0.0.10)
- instance-b(例:10.0.0.11)
- ポート:いずれか(Any)
- ロード・バランシング・ポリシー:5タプル・ハッシュ
ロード・バランシング・ポリシーは、まずはデフォルトの 5タプル・ハッシュで開始(悩んだらデフォルトでOK)。
セキュリティ・リスト(重要)
画面に「作成後にセキュリティ・リスト・ルールを手動で構成してね」という警告が出る通り、ここをサボるとヘルスチェックが通らずCriticalになります。
- 「自動的に追加」でもいいし、運用ポリシー的に嫌なら「手動」でもOK
- 手動の場合は、少なくとも
- NLB → バックエンド(例:80/udp,tcpなど必要ポート)
- ヘルスチェックの到達(下の「ヘルスチェック送信元IP」の話)を許可する必要があります
ヘルス・チェック・ポリシー
ここが今回のハマりどころでした。
- プロトコル:HTTP
- ポート:80
- 間隔:10000ms
- タイムアウト:3000ms
- 再試行回数:3
- URLパス:/
- ステータス・コード(期待値):301(環境によって変えてください。最初は 200 にしていた)
このままだと、nginx側が「HTTPは全部HTTPSへ301」みたいな設定の場合、ヘルスチェックの期待値とズレます。
つまずいた点:バックエンドヘルスがCriticalで転送されない
NLBを作っても、バックエンドヘルスが Critical だと当然転送されません。今回はヘルスチェックの戻り値が原因でした。
nginxの設定がHTTP(80)をすべてHTTPSへ 301リダイレクトする形になっていました。
server {
listen 80;
listen [::]:80;
server_name donguri3.net www.donguri3.net;
return 301 https://$host$request_uri;
}
この状態でプライベートIPに curl -I すると、当然 HTTP/1.1 301 が返ります。つまりnginxは“正常に”301を返している。
しかし、NLB側が「HTTPで200を期待」みたいな設定だと、301は不健康扱いになってCriticalになります。
問題なければ全体的なヘルスの項目がOKになり、ネットワーク・ロード・バランサが機能します。
まとめ:原因不明でも、追加0円で入口は強くできる
OCI1が「起動中なのに不通」になり、コンソールで見ても原因が掴めない。OCIの障害情報もない。OCI2は正常。しかもOCI1だけメトリクス欠損が出る――この条件だと、原因究明だけで戦うと入口停止が続きます。
そこで、OCI2にも入口(WireGuard + nginx)を用意し、Always Freeの範囲で Network Load Balancer(NLB) を作って入口を二重化しました。
ヘルスチェックはnginxの301挙動に合わせて期待コードを301にし、まずは「止まらない入口」を追加コスト0円で実現。原因調査は後からでもできますが、入口停止のストレスは先に消せます。
同じ問題に引っかかった人はぜひ試してみてください。