Docker不要。WSL2とPodmanで作る軽量ローカルLLM環境構築
現在、複数のAIを連携させる「マルチエージェント」の構築を試みています。
その際、すべての処理をSaaS(ChatGPTやGeminiなど)に任せるのではなく、手元のローカルLLMと組み合わせたハイブリッド構成にしようと考えました。
ローカルLLMの環境構築には、Windows側を汚さないコンテナを利用します。定番のDockerでも良いのですが、DockerはAIを使っていない待機時にも裏側でデーモン(管理プロセス)が常駐し、PCのリソースを無駄に消費してしまいます。今後のマルチエージェント開発に向けて、手元の環境はできるだけ省力化・軽量化しておきたいところです。
そこで今回は、リソース消費が少なく完全デーモンレスで動く「Podman」を使って、WSL2上にクリーンなローカルLLM環境(Ollama + Open WebUI)を構築してみました。
二つのローカルLLMを待機させる
具体的な目標は以下の通りです。
- 環境のクリーン化: Windows側にDocker Desktopを入れず、コンテナ停止時はバックグラウンドプロセスを完全に「ゼロ」にします。
- マルチモデル待機: RTX 3060(VRAM 12GB)の余裕を活かし、日本語に強い軽量モデル(qwen3:4b と gemma3:4b)の2つを同時に立ち上げておきます。
【実体験】Podman移行で私がハマった「5つの罠」
DockerからPodmanへ乗り換える際、私は見事にいくつかの罠にハマりました。以下の対策を知っておけば、無駄な時間を溶かさずに済むはずです。
- GPUが認識されない罠
Dockerの書き方ではGPUが動きません。代わりに「CDI」という、NVIDIAが提供する「コンテナへGPUを直結させる公式の仕組み」を使います。 - イメージがダウンロードできない罠
Podmanはセキュリティに厳しく、省略名を弾きます。必ず docker.io/ollama/ollama のようにフルパス(完全修飾名)で指定します。 - チャット履歴が消える罠
Windows側のフォルダを直接指定すると、権限エラーでデータベースが壊れます。Podmanが安全なデータ置き場を自動作成してくれる「名前付きボリューム」を使用します。 - 5分放置でロードが長くなる罠
デフォルトでは、5分間チャットをしないとVRAMからモデルが消去されます。環境変数に OLLAMA_KEEP_ALIVE=-1 を設定してタイムアウトを無効化し、常にVRAMへ常駐させます。 - モデルが同時に読み込まれない罠
マルチエージェントを想定して2つのモデルを切り替えて使おうとしても、デフォルトでは「1度に1つのモデルしかVRAMに乗らない」仕様になっています。環境変数に OLLAMA_MAX_LOADED_MODELS=2 を明記し、2つのモデルの同時待機を許可します。
【最短構築手順】docker-compose.yml
前提として、WSL2(Ubuntu 22.04以降)環境が用意されているものとします。
ステップ1:PodmanとGPU連携ツールのインストール
Ubuntuのターミナルを開き、必要なパッケージをインストールします。
# Podman本体とComposeツールの導入 sudo apt update sudo apt install -y podman podman-compose podman-docker # NVIDIA提供のGPUパススルー用ツールを導入 sudo apt-get install -y nvidia-container-toolkit # CDI(GPU直結の仕組み)の設定ファイルを自動生成 sudo nvidia-ctk cdi generate --output=/etc/cdi/nvidia.yaml
ステップ2:docker-compose.yml の作成
適当な作業フォルダに以下の docker-compose.yml を作成します。前述した「実体験に基づく5つの罠」への対策をすべて盛り込んだ決定版です。
services:
ollama:
image: docker.io/ollama/ollama
container_name: ollama
ports:
- "0.0.0.0:11434:11434"
environment:
- "OLLAMA_KEEP_ALIVE=-1" # 罠4対策:タイムアウト無効化
- "OLLAMA_MAX_LOADED_MODELS=2" # 罠5対策:2モデルの同時待機
volumes:
- ollama_data:/root/.ollama # 罠3対策:名前付きボリューム
devices:
- nvidia.com/gpu=all # 罠1対策:CDIによるGPUパススルー
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
ports:
- "0.0.0.0:3000:8080"
environment:
- OLLAMA_BASE_URL=http://ollama:11434
volumes:
- open-webui_data:/app/backend/data
depends_on:
- ollama
volumes:
ollama_data:
open-webui_data:
ステップ3:起動とAIモデルの取得
絶対に sudo を付けず、一般ユーザーのまま起動コマンドを叩きます。
podman-compose up -d
起動したら、Ollamaコンテナ内で使いたいモデルをダウンロードします。
podman exec -it ollama ollama run qwen3:4b podman exec -it ollama ollama run gemma3:4b
ブラウザ上の設定でもモデルを追加できます。
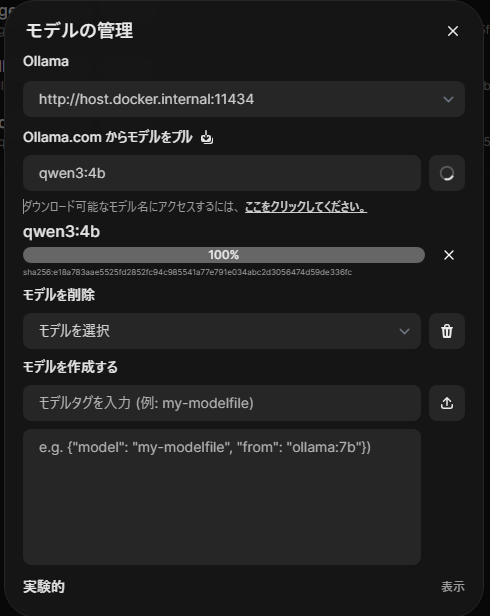
ステップ4:WebUI側でのタイムアウト無効化
Windowsのブラウザから http://localhost:3000 にアクセスし、Open WebUIにログインします。画面左下の「管理者パネル」>「設定」>「一般」>「高度なパラメータ」と進み、「Keep Alive (Ollama)」の項目を -1 に変更して保存します。
【まとめ】手元の資産を活かすクリーンな土台が完成
不要になれば podman-compose down で落とすだけで、常駐プロセスもVRAM消費も完全に「ゼロ」になります。
定番のDocker Desktopから離れ、少しの工夫でPodmanを導入したことで、限られたリソース(RTX 3060)を無駄なく使える非常にクリーンな環境が手に入りました。
この身軽なローカルLLM環境を土台にして、次回は実際にSaaS(Gemini等)と連携させる「マルチエージェント」のシステム構築を進めていきます。